


結論からいいます
Excelで受け取ったデータを加工するためにテキストエディタ(秀丸)の取り込んで保存しようとしたら「日本語Shift-JIS」にない文字が使われているとのメッセージが表示されました。
その文字とは丸囲み数字で通常使う「①(U+2460)」ではなく「➀(U+2780)」の方だったので、「U+2460」の方の「①」に置換をかけました。
ところが、想定していたターゲットの 「➀(U+2780)」 だけではなく、思いもしない文字まで置換されていたための事故になりました。
テキストエディタで置換すれば4個だったはずなのにExcelで置換してしまったために、なんと211個も置換されていたのですが、そこできずくこともできたはずなのに不注意でした。
そこで、何が起きていたのかを調べてみました。
環境依存文字
マイクロソフトのアプリで普通に使う丸囲み数字ですが、これは「環境依存文字」です。普通にWindowsでは使っていますが、メールやwebでは正常に表示されないことがあったようです(「環境依存文字」は「機種依存文字」ともいうようです)。
そもそも、事の発端はJISの規格に漏れがあり、実用文書作成において不都合がある文字セットを各社が拡張領域を使って各様に拡張したのだそうですが、なかでもNECのPC-9800のシェアが大きかったため、その残骸を継承することとなったようです。
これと似たようなことはNTTがiモードで絵文字を組み込んだものの、キャリアが異なれば互換性を持たなかったため意図しない絵文字が相手に届くようなことになったのと同様です。賢い人たちがシェアを争うために利便性を無視している構図を繰り返しているうち、文字コードはUnicodeになり、携帯はスマホに駆逐されました。
結局は、「Unicode」という考え方で文字コードを業界で規格化しようとなり、ほぼ、機種依存文字は吸収されるようになったとのことです。一般的に使われているのは「UTF-8」じゃないかと思いますが他にも「UTF-16」「UTF-32」があるようですが、詳細は理解が追いついていません。
事故の概要
肝心な事故の発生について説明します。
丸囲い数字には「➀(U+2780)」と「①(U+2460)」があります。「U+2460」の方の文字はShift-JISにもあるのでテキストエディタであろうがExcelであろうが問題なく使えますが、「U+2780」のほうはShift-JISでは文字セットが用意されていませんので機種によっては正常に表示できないことになる可能性があります。
それで「U+2780~2789」の文字をExcelで「U+2460~2469」に置換をしたことで思わぬ副作用が発生してしまったというわけです。
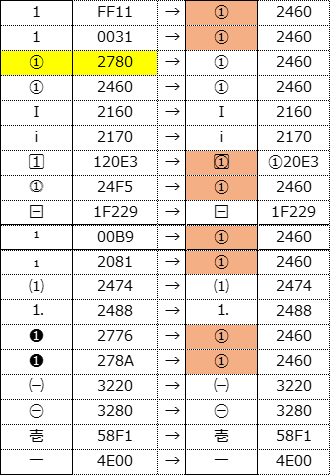
ターゲットは黄色で塗った「➀(U+2780)」でしたが、右の色塗りのように副作用が発生しています。事故のケースでは全角の「1」と半角の「1」が「①(U+2460)」に置き換わってしまっていることです。
どういう判定で「イチ」だけで8個も置換されるのかの原理と意図は不明ですが、マイクロソフトには深い考えでもあるのでしょう。
ちなみに、
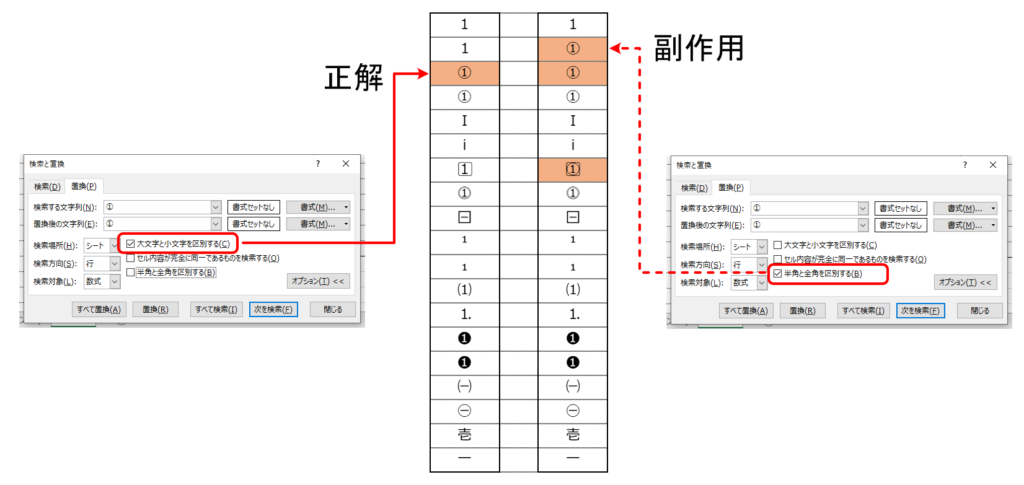
Excelの置換のオプションで「大文字と小文字の区別をする」にチェックを入れておけばターゲットだけの置換になっていました。
「半角と全角を区別する」にチェックを入れておくと、半角数字が置換されていました。これだと「NG」ですが、オプションを指定しないよりはちょっとはマシになりますが半角数字が置換されるので事故になります。
Excelでの置換には十分な注意を払う必要があるという教訓でした。仕様なのかバグなのかは不明です。
Wordでは、このようなことは起きません。

