<div><hr></div>
<div style=”text-align: center; “>
<font size=”4″><br></font><font size=”4″><a href=”https://word-craft.net” title=”頓活” target=”_blank“>
<img src=”http://wordcraft.greenbiz.co.jp/images/03.png” alt=”頓活” title=”頓活” align=”middle” border=”1″ hspace=”0″ vspace=”0″ width=”227″ height=”247″></a>
</font>
</div>
<div style=”text-align: center;”><font size=”4″><a href=”https://word-craft.net” target=”_blank”>文書管理いたしましょう</a></font></div>
<div style=”text-align: center;”><font size=”4″><a href=”https://word-craft.net” target=”_blank”>詳しいことは、こちらをご参照下さい</a></font></div>
<div style=”text-align: center; “><br></div>
赤字にしたところを直す、あるいは行を削除したいのです。HTMLのファイルは1629ファイルあります。これを「awk」で加工します。といっても前処理があります。
ダウンロードしたHTMLファイルの文字コードは「UTF8」なので、windowsのawkで処理するためには「S-JIS」にしなければなりません。どういうわけか、マイクロソフトは世界標準のつもりでいるようで、世界の潮流とは少し違うことを押し通そうとしています。
そこで必要になるのが文字コード変換です。ツールは定番の「nkf」を使います。
awkで加工するためには「変換元」と「変換先」が必要になりますので変換元の「html」拡張子を「txt」にリネームします。
ren *.html *.txt
コマンドラインからリネームをかけます。
nkf -s - -overwrite *.txt
nkfを使って「utf-8」を「s-jis」にして上書きしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/文書管理いたしましょう/{ next; } { split(FILENAME,nn,"."); nn[1]=nn[1] ".html"; sub("word-craft.net¥" title=¥"頓活¥" target=¥"_blank¥"","word-craft.jp¥" title=¥"頓活¥""); sub("word-craft.net¥" target=¥"_blank¥"","word-craft.jp¥""); sub(/width="227"/,"width=¥"580¥""); sub(/height="247"/,"height=¥"400¥""); sub(/詳しいことは、こちらをご参照下さい/,"つたないブログはコーポレートサイトで!") print>nn[1]; } |
スクリプトは例によって「step1.awk」として「script」フォルダに入れます。
「/文書管理をいたしましょう/」が文字列中に出現すれば「next」、つまり次の行を読みに行きます。これで1行削除ができます。
split(FILENAME,nn,”.”);
大文字の「FILENAME」は、読み込むファイル名を取得する約束語です。それにsplitを「.(ドット)」でスプリットして「nn」と名づけた配列に格納しています。
HTMLのファイル名は「000001.html」~「001629.html」になります。
nn[1]=nn[1] “.html”;
nn[1]にはファイル名の「.(ドット)」から前方の文字列が入っています。その文字列に拡張子「.html」をつけています。単に並べて書くだけです。
sub(“word-craft.net¥” title=¥”頓活¥” target=¥”_blank¥””,”word-craft.jp¥” title=¥”頓活¥””);
sub(“word-craft.net¥” target=¥”_blank¥””,”word-craft.jp¥””);
sub(“word-craft.net¥” title=¥”頓活¥” target=¥”_blank¥””,”word-craft.jp¥” title=¥”頓活¥””);
「 “word-craft.net” title=”頓活” target=”_blank”」を「 “word-craft.jp” title=”頓活” 」 に加工しています。次の行も似たような加工です。「sub」は正規表現で加工前のパターンを定義できますが、正規表現なりの面倒さがあるので「文字列対文字列」で加工をしています。
その際に「”(ダブルクォーテーション)」を「¥」でエスケイプしています。
sub(/width=”227″/,”width=¥”580¥””);
sub(/height=”247″/,”height=¥”400¥””);
これは「227」を「580」、「247」を「400」に置換しています。
sub(/詳しいことは、こちらをご参照下さい/,”つたないブログはコーポレートサイトで!”)
文字列の置換をしています。変換元に正規表現の「/」を使っていますが、「”」でも同じです。
print>nn[1];
print先を標準出力に出しています。ファイル名は「nn[1]」になります。
ちなみに「>>」と「小なり」を2個続けると「アペンド」になるので、一つのファイルに合体していくことができます。
awk -f script¥step1.awk *.txt
とすることで、1629ファイルのtxtファイルから「html」ファイルを生成します。
わずか10行足らずのスクリプトでかなりの数のファイルをいとも易々と加工しているのが「awk」という50年前のスクリプト言語です。VBAのようなpascal崩れの言語などに比べて実の簡明で覚えやすく、威力は使い次第ではかなり強力だと思います。
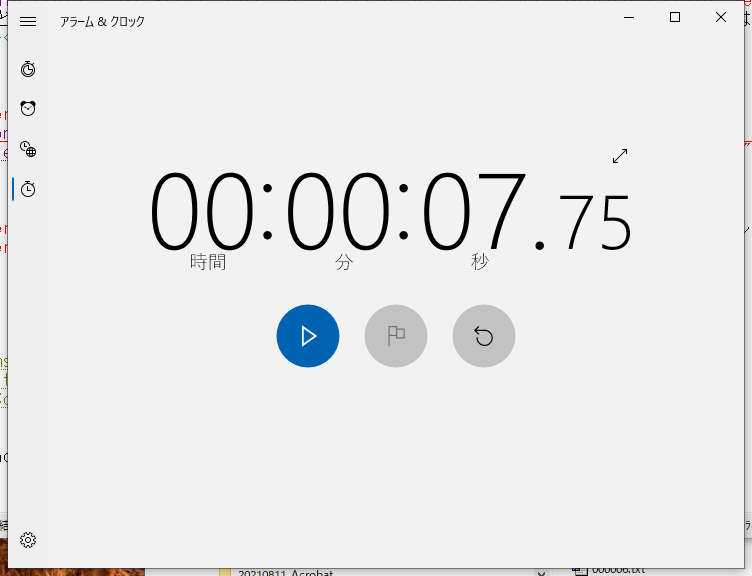
約8秒でした。
nkf -w –overwrite *.html
とすることで「s-jis」から「utf-8」にしてFTPでもとの場所に書き戻して終わりです。
C言語が速度的に優れているというのは、テキストファイルのストリーム処理などでは有効なことだとは思っていません。この手の処理ではawkに圧倒的な利点をあげることができると思います。