


Wordで作った「大鏡」の概要があります。A4で「187ページ」あります。文字数にして「134,171文字」あります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ gsub(/[ぁ-ん]+/,"\n"); gsub(/[ァ-ヶ]+/,"\n"); gsub(/=+/,"\n"); gsub(/[、|。]+/,"\n"); gsub(/[〈-】]+/,"\n"); gsub(/[\(|\)]+/,"\n"); gsub(/[(|)]/,"\n"); gsub("[ | ]","\n"); gsub(/[0-9]+/,"\n"); gsub(/[0-9]+/,"\n"); gsub(/[A-z]+/,"\n"); gsub("-","\n"); gsub("--> ",""); gsub(/・/,"\n"); gsub(/ー/,"\n"); gsub(/★/,"\n"); gsub(/\./,"\n"); gsub(":","\n"); print; } |
step1.awk
[ぁ-ん]+ は、ひらがなの文字コード範囲をしめしており、「+」によって1文字以上連なっていたら「改行」するということになります。カタカナも同様です。文字コードを範囲で示して改行に変えています。「|」の場合は、どちらかという意味になります。[¥(|¥)]としているのは、半角かっこはメタ文字なので「¥」でエスケープしています。
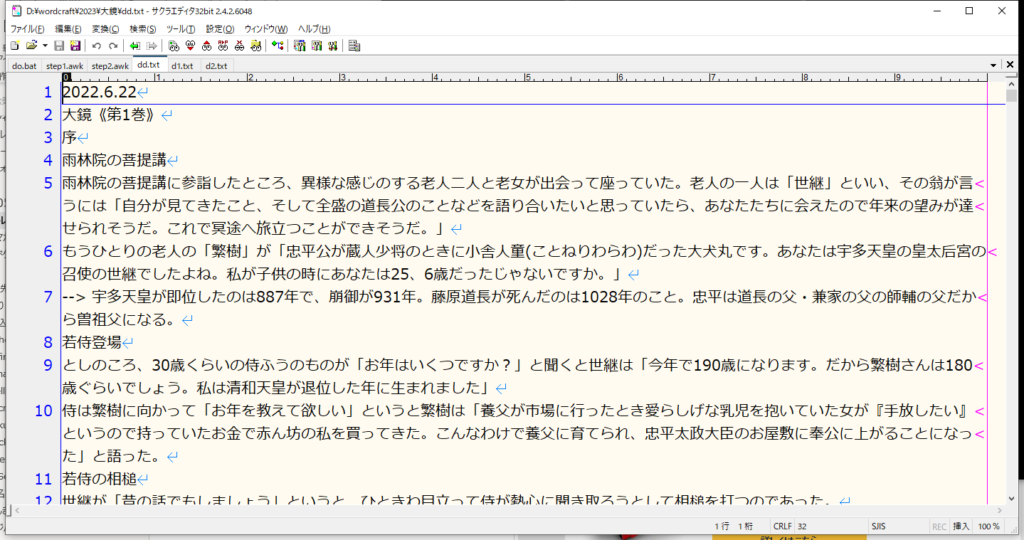
ワードからコピペでテキストエディタに貼り付けました。「2,529行」ありました。「step1.awk」を通すと、ひらがな等が続く部分は全て改行にしてあるため「42,504行」になりました。

|
1 2 3 4 5 6 7 8 9 10 |
length($0)<=1{ next; } { buff[$0]+=1; } END{ for(i in buff) print i "¥t" buff[i]; } |
「length($0)<=1」としているのは、漢字1文字、あるいは改行のみの行を読み飛ばしています。
「buff[$0]+=1;」は、連想配列に漢字熟語を格納しながら、同じ語彙の出現回数をカウントしています。
この書き方は連想配列の出力の定番です。「4,980行」になりました。

これをエクセルに貼り付けてから、一般語にフラグを立てていきます。なぜ消さないかというと、本体のワードに手を加えたときに、再利用できるからです。
Excelを使ったリスト整理
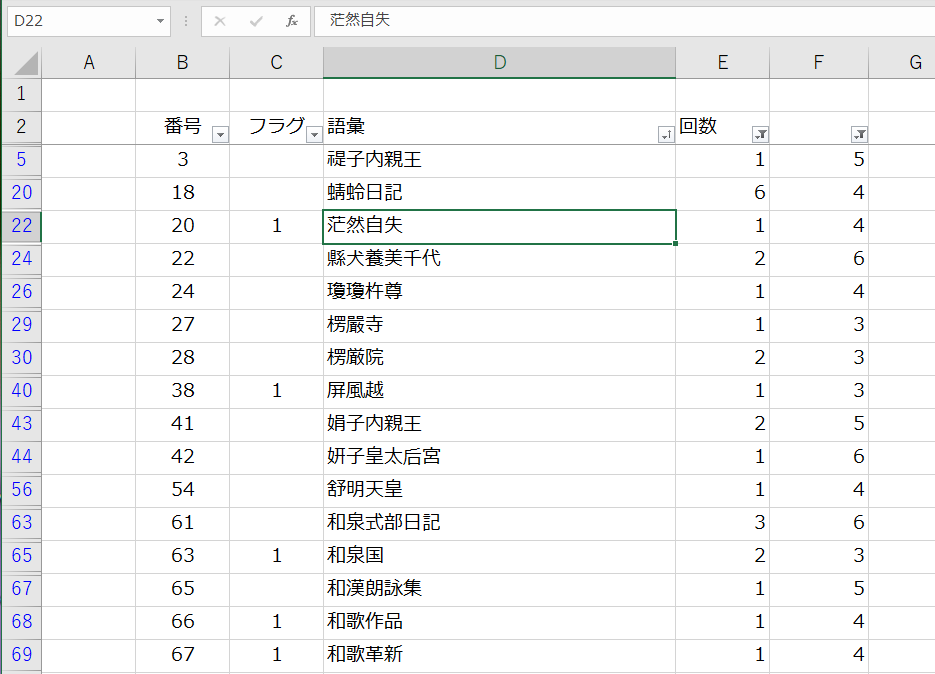
E列では、出現回数を「10回以下」としF列は文字列長を「3文字以上」としています。
「10回以下」としている理由は、多く出現する漢字熟語はそれなりに重要な熟語である可能性が高いと思うからです。
「3文字以上」としている理由は、漢字熟語で「2文字」には、一般語が多いと思うからです。で、先に「2文字熟語」から一般語にフラグを付ける前処理をしてから、3文字以上を対象にしているからです。
索引を作る目的は、その単語がどのページに出現しているかの道先案内をするためなので、一般語は排除しなければなりません。逆を言えば、一般語の辞書を作れば、索引作成の生産性が上がるので蓄積していくことには価値があります。
このような作業をしていると誤植が見つかります。あるいは、スクリプトの追加修正をする必要が生じたりします。そうすると、いままでExcelでしていた作業が無駄になってしまわないようするためのスクリプトの用意が必要になります。
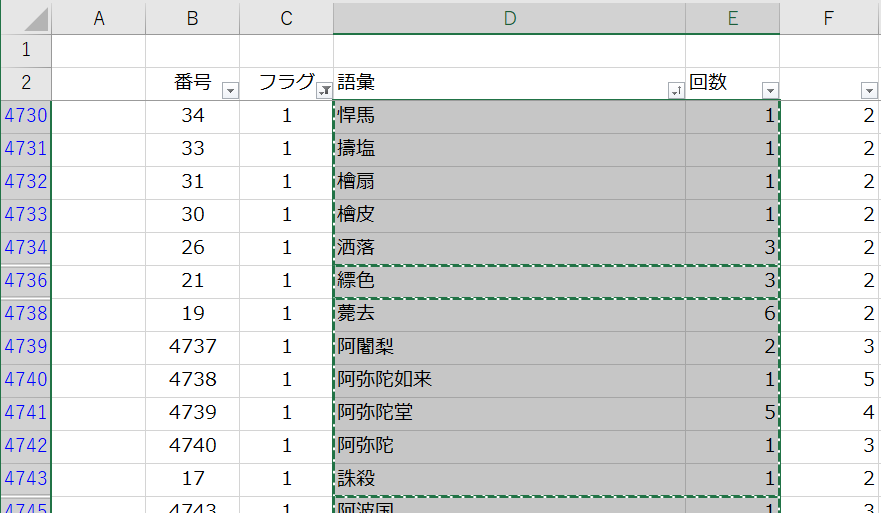
フラグを「1」にした熟語は排除対象ですので、熟語語彙と出現回数の2列をテキストファイルに貼り付けます。このファイル名を「list.txt」としておきます。
新たに作成した「d2.txt」から「list.txt」を排除した索引候補にします。
元のwordに手を加える都度に、この作業を繰り返していきます。そのスクリプトは、
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BEGIN{ FS="¥t"; OFS="¥t"; } FLG==1{ buff[$2]=$1; next; } { if(buff[$1]=="") print; } |
「FLG==1」の間だけ、「list.txt」のファイルを読み込みながら「buff」に取り込んでいます。「list.txt」を読み込み終わると「d2.txt」を読み込み始めます。
|
1 |
awk -f script¥step3.awk FLG=1 list.txt FLG=0 d2.txt>d3.txt |
これで作られた「d3.txt」が、ほぼ索引の候補となるわけです。実際には、相互参照のための処理や、親子関係のための処理などがありますが、それについては別の記事にあげます。

