


「変数」というのは、本来はメモリ上にあるアドレスと領域のことになります。「配列」なども同様で先頭アドレスと大きさがメモリ上に確保されます。変数とか配列の名前はあくまでも人間のためのものでコンピュータにとってはコンパイルするタイミングでアドレスと領域の確保でしかありません。
ところが、インタープリタは出たとこ勝負なので、変数や配列がスクリプトに現れた時点でインタープリタが領域を確保するのでしょう。おそらくはポインタを駆使して動的に領域を確保するのだと思います。記憶は薄れていますが、その昔は「連想配列」とは呼ばず「ハッシュ」と言っていたように思います。
この「ハッシュ」もブロックチェーンなどでファイル名の暗号化で脚光を浴びるようになりましたが、昔は「ハッシュテーブル」として衝突回避を考慮しながらも分散のバランスが、いいような散らし方ができれば、高速なデータサーチができる手法として使っていたと聞いた覚えがあります。
「連想配列」と日本語で言う部分は英語では「associative arrays」と書かれています。「associative」を英語の辞書では「連想の、連合の、連帯の」となっているので、そこからまことしやかな感じのする「連想」が使われたのだと思います。
さて、余談はここまでにしてawkの連想配列がとても便利なことを示します。
|
1 2 3 4 5 6 7 |
{ dd[FILENAME]+=1; } END{ for(i in dd) print i "¥t" dd[i]; } |
スクリプトの説明
dd[FILENAME]+=1; ← ここが「連想配列」になります。
FILENAME:は予約語で、現在読み込んでいるファイルの名前になります。
なにをしているのかというと、ファイル名ごとに行数をカウントしています。
ボディは、たった1行です。
for(i in dd) ← 連想配列を扱う時の常套句です。
ただし、出力はソートがかかっているわけではないのでExcelでソートします。
そのためにはタブセパレーションのほうが都合がいいです。
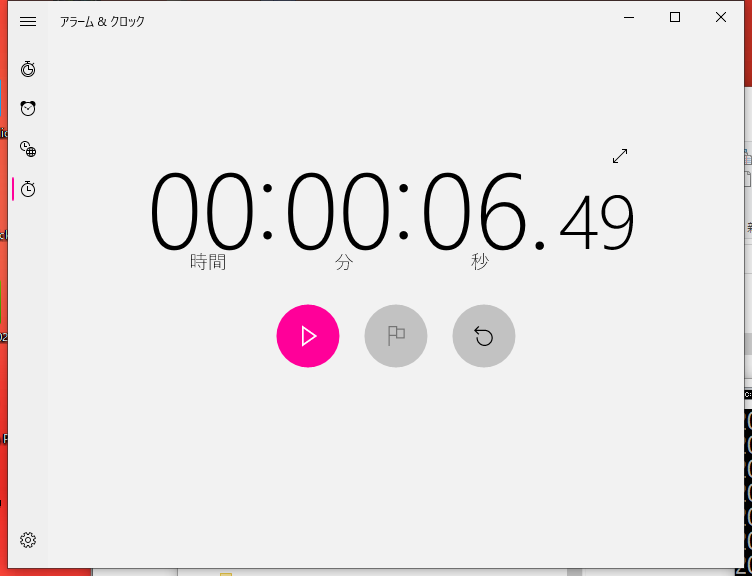
awk -f script¥step1.awk *.csv>dd.txt
このスクリプトを実行したら、約7秒でした。
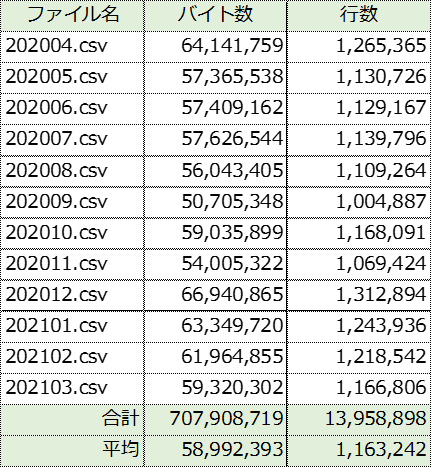
テキストファイルで1ファイルの平均が116万行で60メガバイトあります。この12ファイルをカウントすると約1400万行を7秒でカウントしています。そのスクリプトは7行で、3分もあれば書けます。スクリプトの中核は「dd[FILENAME]+=1」のたった1行で、仕事をします。
ファイルI/Oの呪文やら使用するライブラリの定義やら変数の宣言やら、なんにもいりません。標準入力からワイルドカード(ここでは「*」アスタリスク)で複数のテキストファイルを読み込んで、標準出力に書き出す。
ルーズな自分にとって、この「寛容」さは頭が下がる思いです。
今日はここまで。次回はクロス集計をやりましょう!

