


awkでクロス集計をするのは実に簡単です。
サンプルで使っている1400万行のテキストデータのフィールド構成は、
1.出荷センター
2.日付(YYYYMMDD)
3.ユーザーID
4.金額
5.性別
6.年齢
7.住所地(都道府県)
まずは単純集計で、住所地ごとの売上金額を調べてみます。
|
1 2 3 4 5 6 7 8 9 10 |
BEGIN{ FS=","; } { dd[$7]+=$4; } END{ for(i in dd) print i "¥t" dd[i]; } |
スクリプトの説明
FS=”,” カンマセパレーションであることを宣言しなおしています
dd[$7]+=$4; 連想配列で7番目の「住所地」を配列の添え字にして、その添え字に対して4番目の「金額」を加算しています。
END これを説明するのを忘れていました。
BEGIN と同様にスクリプトが実行されると1回だけ読み込まれて実行されます。
「BEGIN」は最初の一回だけ、「END」は最後に一回だけ実行されます。
for(i in dd) 連想配列を呼び出す定型的な記述です

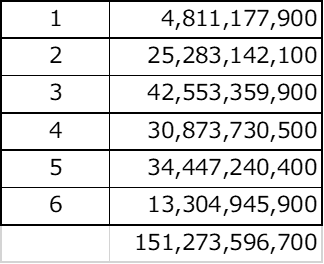
スクリプトの実行時間は30秒です。47都道府県の1年間の売り上げは「151,273,596,700円」でした。概ね1500億円。都道府県で最大の売り上げが「140億円」で最小の売り上げが「1億円」、平均が「32億円」という結果でした。
年齢分布を出してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
BEGIN{ FS=","; } { if($6<30) nen=1; else if(($6>=30)&&($6<40)) nen=2; else if(($6>=40)&&($6<50)) nen=3; else if(($6>=50)&&($6<60)) nen=4; else if(($6>=60)&&($6<70)) nen=5; else nen=6; dd[nen]+=$4; } END{ for(i in dd) print i "¥t" dd[i]; } |
年齢区分を10歳刻みにしてみました。そのクラスを連想配列の添え字にして売上金額をクラスごとに加算しています。
実行時間が34秒でした。
クラス1が20代、2が30代、3が40代、4が50代、5が60代、7が70代以上です。この結果自体は適当なデータを前提しているので意味を解釈することは無意味ですが、年齢区分を入れても4秒しか処理時間が増えていないことはawkインタープリタの内部処理は非常に賢いのでしょう。
では、本日のお楽しみのクロス集計です。
dd[$7 “¥t” nen]+=$4;
連想配列の添え字に「$7 “¥t”」を書き加えただけです。
46鹿児島県 6 45323600
23愛知県 1 5416400
23愛知県 2 35107100
23愛知県 3 114141700
23愛知県 4 56122300
38愛媛県 1 109686600
01北海道 1 35076400
23愛知県 5 62854000
01北海道 2 237412600
38愛媛県 2 530851900
23愛知県 6 23491900
38愛媛県 3 678788900
01北海道 3 540915500
・
・
・

このように各都道府県・年齢クラスごとに金額が加算されています。このファイルをExcelに張り付けてピボットテーブルで集計をすると1瞬でクラス集計表になります。
プラス5秒の40秒でした。
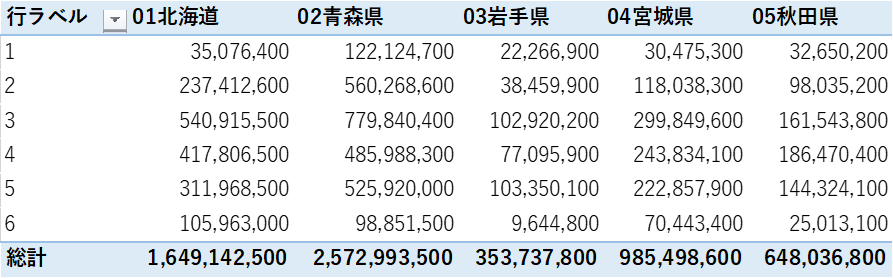
こんな感じで47都道府県の金額を年齢クラスでクロス集計することができます。
データ件数は、約1400万件で金額が1500億円のクロス集計は、22行のawkのスクリプトによって40秒で集計することができました。
注意しなければいけないことは、出力はawk任せの出力順になります。これをExcelのピボットで表に並び替えるときは、ピボットがソートをしてしまうので、ソートしたときに期待通りの並びになるように工夫をしておかなければなりません。
例では、あらかじめ都道府県に府県コードを付けています。

