















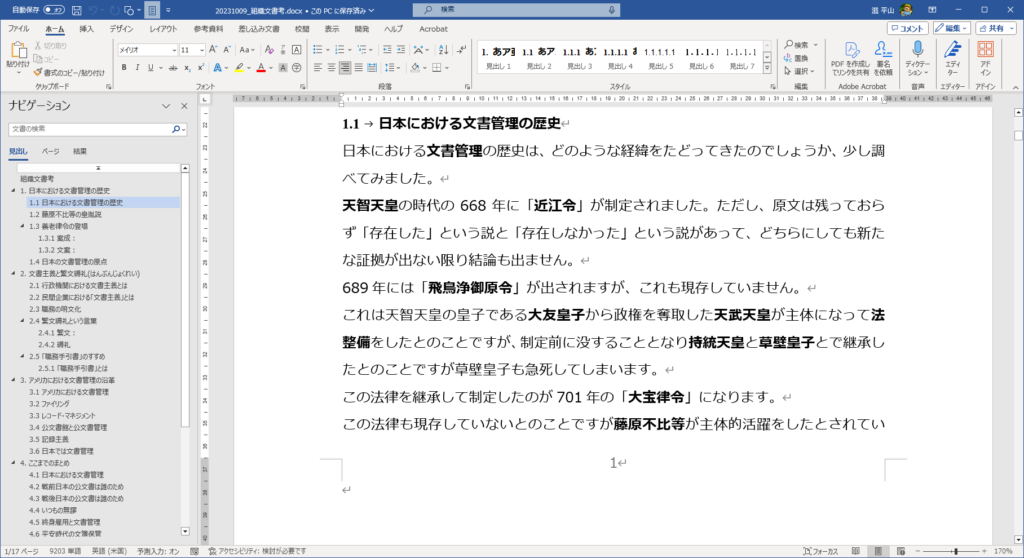
ワードで作成した文書に、索引として取り出そうと思う語句をボールドにします。このワード文書をMarkDownフォーマットに変換します。
Markdown とは、「文書を記述するための軽量マークアップ言語」のように説明がされていますが、簡易的な約束をテキストファイルに付けることで、ブログソフトや WordPress でHTMLの書式に展開するテキストファイルのkとです。
変換は「Typora」を使いますが、何を使ってもそれほど変わりはないと思います。ちなみに、「docx2md」というツールも重宝していますが、使えるようにするのにひと手間かかりますので、2千円ほどかかりますが「typora」を前提とします。
上図のワード文書から Markdown に出力したものが下図のようになります。
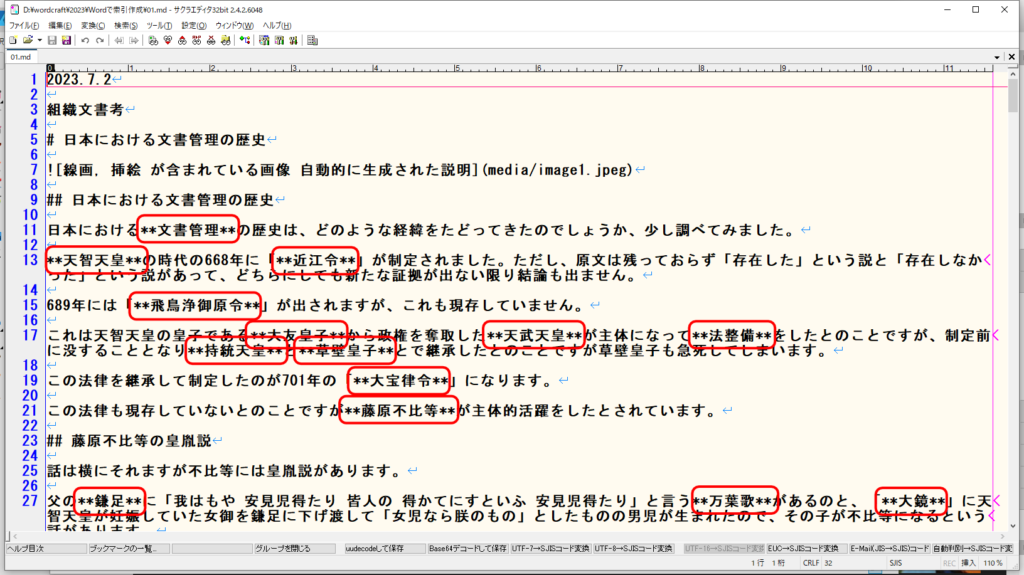
ちょっと見た目がうるさくなってしまいましたが、赤丸で囲ったところがボールドのところです。「**」アスタリスク2つで挟んでいます。
|
1 2 3 4 5 |
# awk -f script\saku01.awk 01.md>01.txt { gsub(/\*\*/,"\n●\n"); print; } |
スクリプトを説明すると、「gsub」関数を使ってアスタリスクが二つ連続するならば、改行後に「●」を付けて再度改行をしています。
|
1 2 3 4 5 6 7 8 9 10 11 |
# awk -f script\saku02.awk 01.txt>02.txt /^●/{ ++cc; } { if(cc%2==1){ print $0; }else if(cc%2==0){ next; } } |
「●」が出たらカウントしています。そのカウントを2で除して1余る、つまり奇数ならば出力する。割り切れたら次の行を読みに行く。
|
1 2 3 4 5 6 7 |
# awk -f script\saku03.awk 02.txt>03.txt /^●/{ next; } { print; } |
「●」は読み飛ばす。それ以外は出力する。
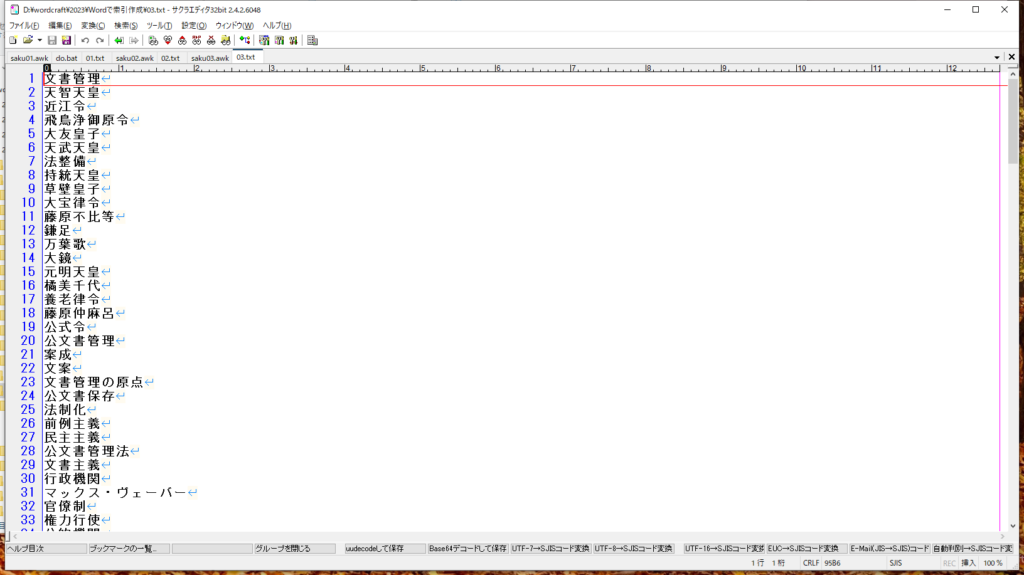
これで、ボールド語句だけを取り出しました。
|
1 2 3 4 5 6 7 8 |
# awk -f script\saku04.awk 03.txt|sort>04.txt { dd[$0]+=1; } END{ for(i in dd) print i "\t" dd[i]; } |
連想配列に索引語句を読み込み真柄、同じ語句なら出現回数を加算しています。「for(i in dd)」という書き方は連想配列を出力する定型的な書き方です。
連想配列から出力すると、出力は読み込み順ではなくなるので「sort」が必要になります。
それを、一括で行うバッチファイルで最終的にソートしています。
|
1 2 3 4 |
awk -f script\saku01.awk 01.md>01.txt awk -f script\saku02.awk 01.txt>02.txt awk -f script\saku03.awk 02.txt>03.txt awk -f script\saku04.awk 03.txt|sort>04.txt |
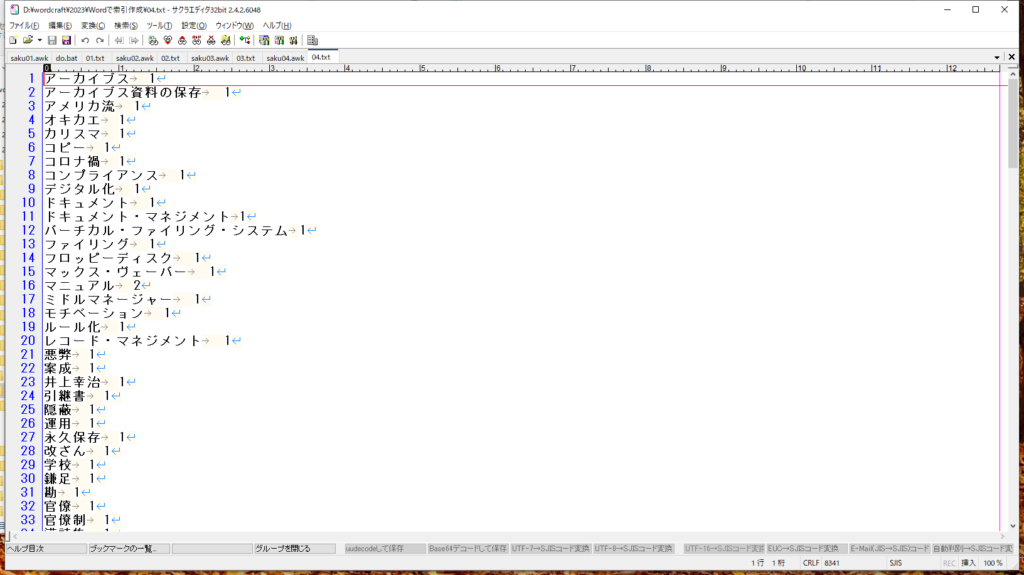
awkのようなフィルター言語では、1つのスクリプトですべてを解決することは面倒なことになります。なぜなら、awkの処理は改行単位だからです。
1行の中に可変で対象とするパターンがあるような場合は、このように順次処理していくことで、実に簡明なスクリプトで成果を出すことができます。

