


サクラエディタで漢字コードを調べてみたら、不思議なことが分かった。
Windowsで使うテキストエディタなので、文字コードはShift-JISである。青空文庫から芥川龍之介の『リチヤアド・バアトン訳「一千一夜物語」に就いて』を例にとって、その不思議について説明する。
Shift-JISの全角文字で漢字の最初の文字は「亜」(889f)となっている。最後の漢字は「熙」(EAA4)なので、正規表現でShift-JISの漢字を網羅するには [亜-熙] でいいことになる。
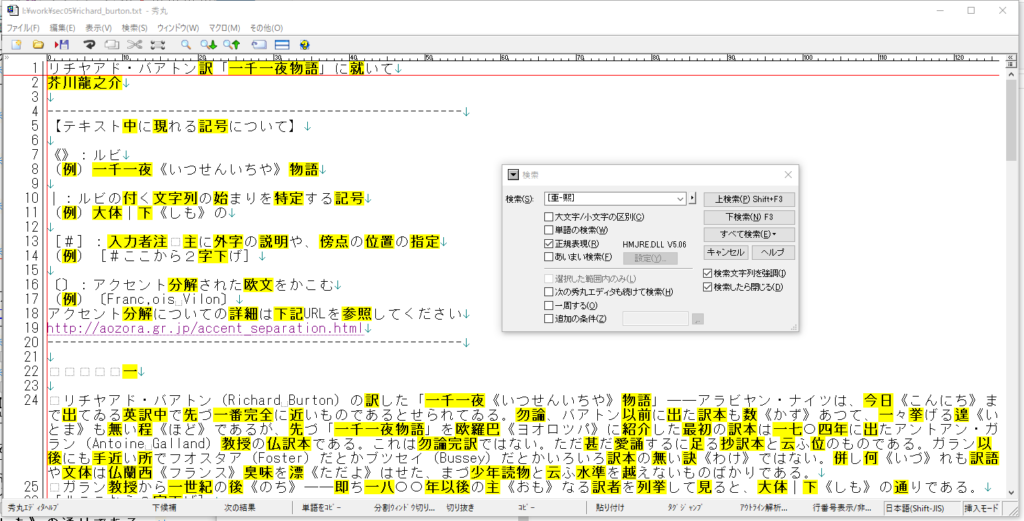
確かに、秀丸で [亜-熙] として検索すると、漢字を全部見つけてくる。
しかし、サクラエディタで同じ検索条件で検索すると、

このように、歯抜けだらけになる。そこで、Shift-JISとUTF-8のコードを併記しているリストを見つけたので、少し加工してエクセルに取り込みUTF-8のコードでソートをかけてみた。
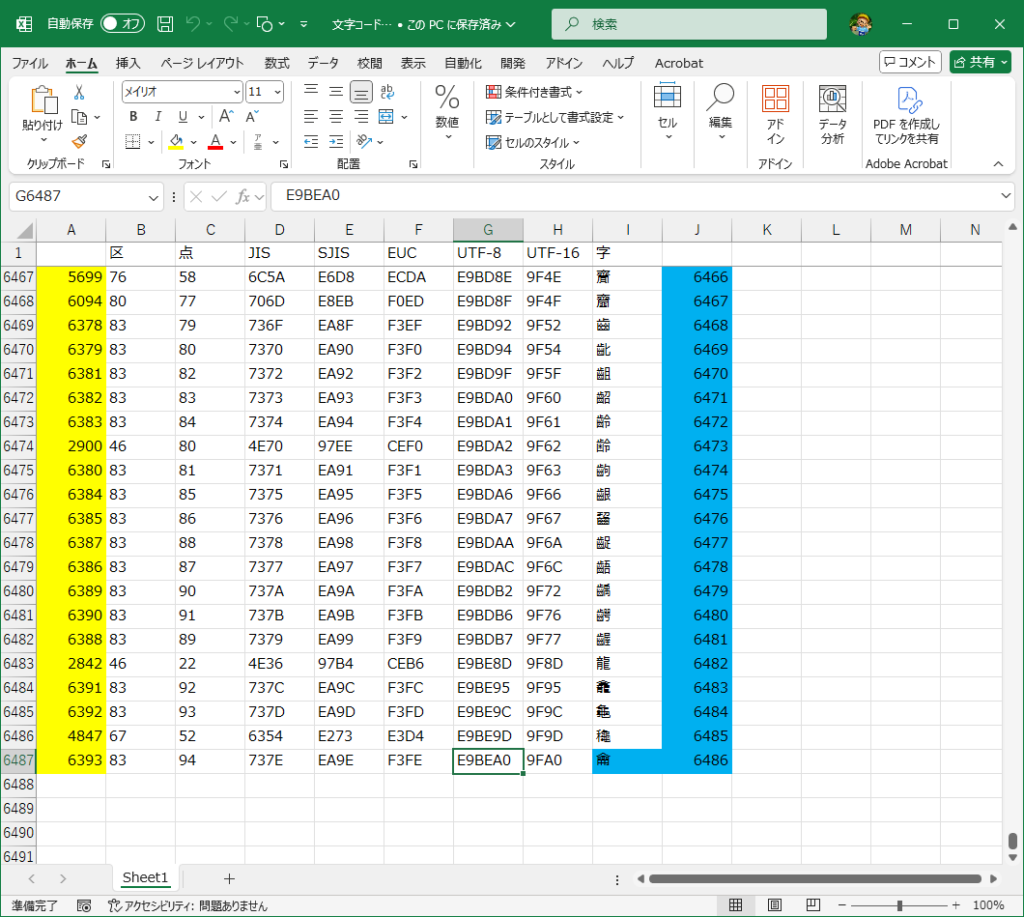
最初の漢字が「一」(E4B880)で、最後の漢字が「龠」(E9BEA0)なので [一-龠] として検索してみた。
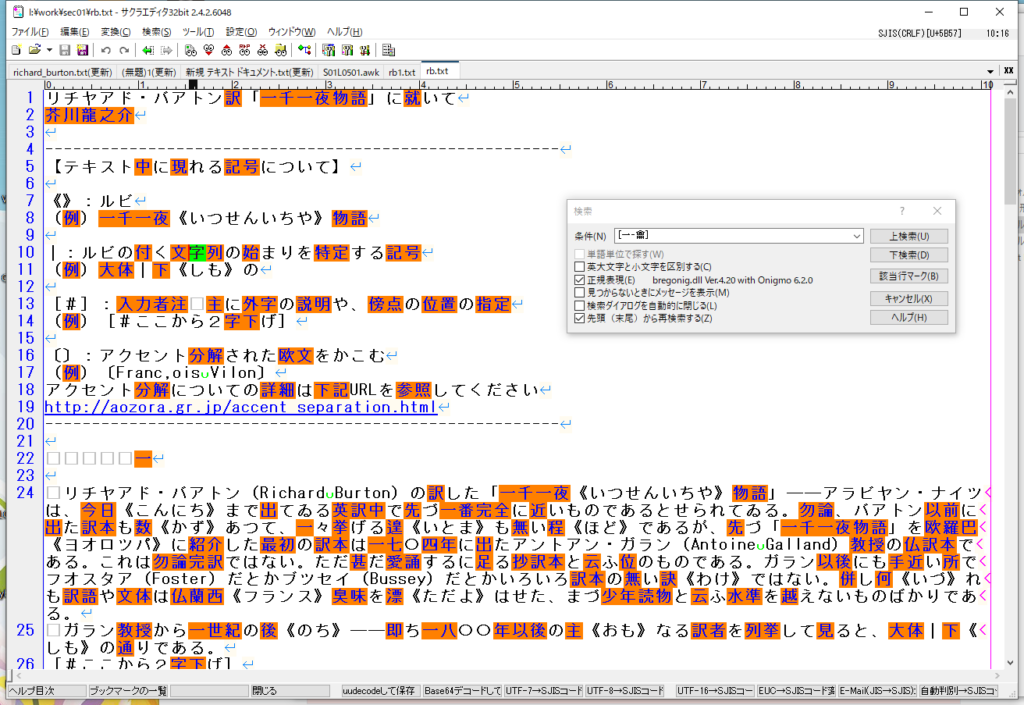
とすると、秀丸のShift-JISのコードで検索したのとまったく同じになった。
実は、awkの正規表現がサクラエディタと同じだったので、漢字の扱いで説明がつかないことになってしまった。昨日から色々調べてみたが「なるほど」という答えは得られなかった。ChatGPTが検索エンジンに「unicode」のコード表が使われているのではないかのような答えがあったが、すっきりとはしなかった。
{
gsub(/[^一-龠]+/,””);
print;
}
「^」を付けているのは、[一-龠] 以外はすべて消去させるということ。で、結果は、
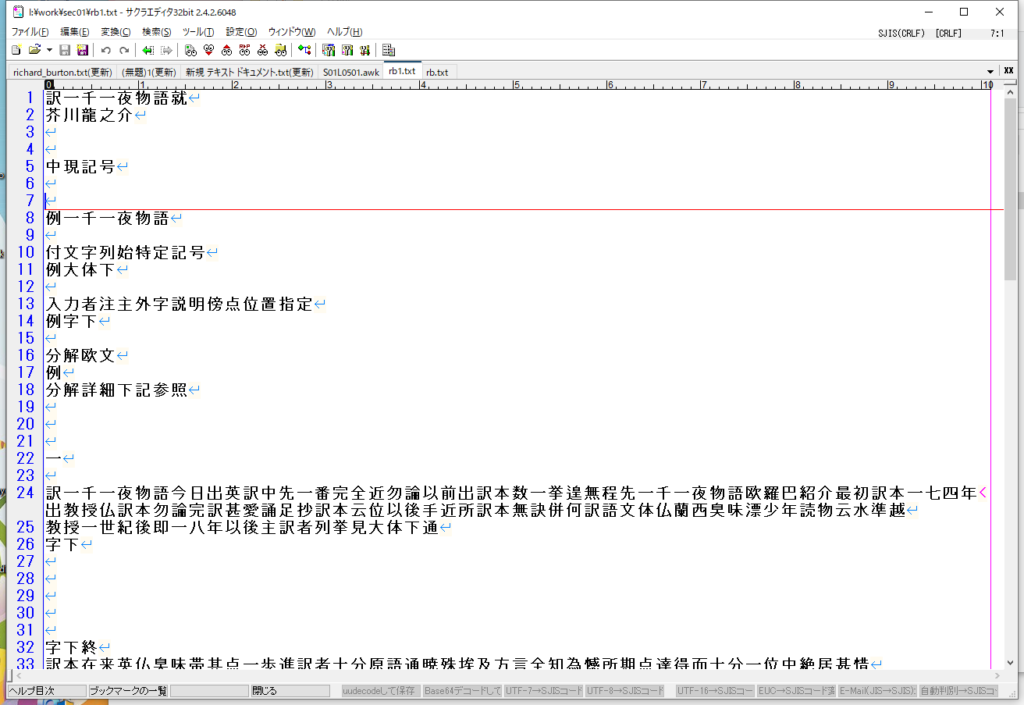
となり、これでなんとか漢字コードをサクラエディタでもawkでも扱えそうになってきた。
しかし、秀丸で [一-龠] の置換で該当する漢字を消去させると、「為(88d7)」「或(88bd)」「亜(889f)」「愛(88a4)」「易(88d5)」「医(88e3)」「謂(88e0)」「遺(88e2)」「異(88d9)」などが残っている。
それは「亜(889f)」から「磯(88e9)」までが除外されているからである。
ということで秀丸の席表現で漢字を対象にするならば [一-龠|亜-磯] とすれば、とりあえずは事なきを得ることが分かった。
