同じデータから条件を変えて抽出した2つのデータがあるとします。
1つが98件で、他1つが94件。
ここから差となる4件を抽出する場合、awkの連想配列を使うととても簡単に抽出できます。
|
1 2 3 4 5 6 7 8 9 10 11 |
BEGIN{ FS="\t"; } FLG==1{ dd[$2]=$0; next; } { if(dd[$2]=="") print $0; } |

「FLG=1」と「FLG=0」で囲んだ部分に数の少ないほうを書きます。そうすると「FLG」が「1」の間、
dd[$2]=$0;
として、連想配列「dd」に取り込まれます。
$2とはデータのコードで、確実にユニークです。
|
1 2 3 4 |
{ if(dd[$2]=="") print $0; } |
ここで、数の多いほうの対象となるファイルを読み込みながら「dd[$2]==””」として、連想配列に取り込まれていないデータを「if」文でチェックしています。
スクリプト書くのに5分程度、処理は秒までかかりません。
ちなみに、100万件と100万4件で中執をかけてみました。100万件と言うのはExcel的に限界に件数と思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
BEGIN{ FS="\t"; t1=systime(); } FLG==1{ dd[$2]=$0; next; } { if(dd[$2]=="") print $0; } END{ t2=systime(); print t2-t1; } |
BEGINとENDに「systime」をいれて100万件読み込んで、100万4件でマッチングをした結果は、「4秒」でした。
「連想配列」は、その昔「ハッシュテーブル」と言って、今のようにデータベースが普通に使われるようになる前のデータ管理に使われていたと聞いたことがあります。
配列の値に非整数を使って、そこからキーを生成するわけです。そのキーはシーケンシャルに並べられるのではなくツリー構造にデータが配置されます。
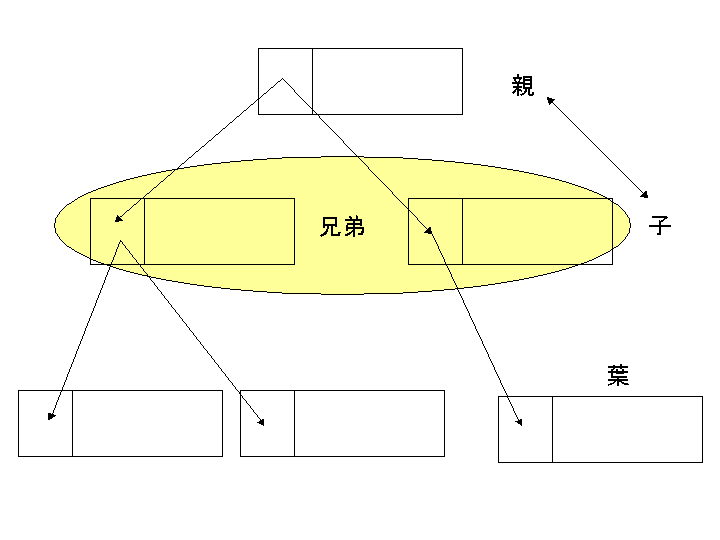
100万件あって、1件ずつ「if」文で合致を探索していくと時間がかかりますが、ハッシュテーブルでツリー構造にデータを配置しておけば、分散がうまくいっていれば、数回の階層を辿れば合致を探索できるわけです。
ただし、分散がうまくいかなければ時間がかえってかかると言われました。awkでは、どのように分散をうまくやってノードをつないでいるのかは不明ですが100万検対100万4件の比較を4秒でやってしまうのですから、大したものです。
それと、スクリプトにかける時間が数分で済むというのもすごいものだと思います。
昨今の言語は約束が多すぎて「覚える」のに時間がかかり、「書く」のに時間がかかり、「処理」にそこそこ時間がかかります。
昔の話をすると笑われますが、連想配列などと言う便利なものがない時代は、ヒープに動的にメモリを確保して、そのメモリのアドレスでつないでいきました。「ポインタ」とか言っていました。それは、配列は固定的だったため、件数が不明で大量の場合は動的にメモリ管理をしなければならなかったからです。
その細則技術が「ツリー構造」でしたが、awkや最近の連想配列に対応している言語には実装されるようになりましたので、大いに利用するべきと思います。