

awkを使ってみよう

awkのことを体系的に説明している記事や、リファレンス的に説明している記事は、インターネットで探せば有用な記事があふれているので、ここでは実際に使っている場面から解説していこうと思います。
最初に説明用のデータを作ったのですが、いつも使うタブ区切りにしてしまいました。一般的にはCSVのほうがいいのかと思ってタブ・セパレーションからカンマ・セパレーションに変える必要があるので、そこのところから説明します。
|
1 2 3 4 5 6 7 8 9 |
BEGIN{ FS="\t"; } { ss=substr(FILENAME,1,6); ss=ss ".csv"; gsub(/¥t/,","); print>ss; } |
スクリプトの説明
テキストデータのセパレータをタブに切り替えます。
コマンドラインから読み込まれるファイルの名前のあたまから6文字を取り出し、末尾に「.csv」という拡張子を付けて変数「ss」にセットしています。
1行中に出現するすべての「タブ」を「カンマ」に置き換えます
[BEGIN]:awkにスクリプトを読ませて実行した時、1回限りで実行する部分です。同様に最後に1回だけ実行するためには[END]があります。
[FS]:1レコードのセパレーターを定義します。デフォルトは半角スペースです。ここでは「\t」、つまり「タブ」区切りに変更することを定義しています。
[FILENAME]:読み込んだファイルの名前がセットされている予約語です。
[substr]:文字列を任意に切り出します。「1,6」とはファイル名の1文字目から6文字切り出す指令になります。仮に
substr(FILENAME,4) のように第3の引数を省略すると4文字目から末尾までという意味になります。
ここではファイル名の1文字目から6文字目までを取得していますが、ファイル名の長さが不定なら「split」を使って「ピリオド(.)」で分けるという方法もあります。
ss=ss “.csv” というのは変数「ss」に「.csv」という文字列を付け加えて変数「ss」に書き戻します。半角スペースで記述すればつながります。「+」とか「&」などでつなぐ必要はありません。ただ、半角スペースで区切って羅列するだけで接続できます。無駄なことは極力排除するのが「awk」です。
[gsub]:「gsub」は1行の中すべてに対して置換をします。最初に出た1か所だけをなら「sub」を使います。
インタープリタとスクリプトとコマンドライン
「インタープリタ」というのは「awk」というアプリが実行主体であって、実行内容を「スクリプト」として扱っています。インタープリタではないものを「コンパイラ」といい、実行形式にするアプリを使うことで単独で実行できるようにすることができます。
UNIXでは、このようなテキストベースのスクリプトでも実行形式にすることができますが、windowsにはその機能がありません。
コンパイラだと、実行形式であるため起動も早いですし、宣言した変数や関数がメモリに展開して実行するため処理速度が速いことがメリットになります。また、実行形式を作るためにコンパイラが判定できるエラーを未然にチェックします。
インタープリタでは厳密なエラーチェックはされず、スクリプトを1行ずつ実行しながら異常があった時点でエラーとして告知の上、処理が停止されます。
変数などもあらかじめ定義する必要はなく、特にawkには堅苦しさや、やかましい規則がないので、ワタシ的には気に入っています。
書いたスクリプトはDドライブの「script」フォルダに入れています。実行は、
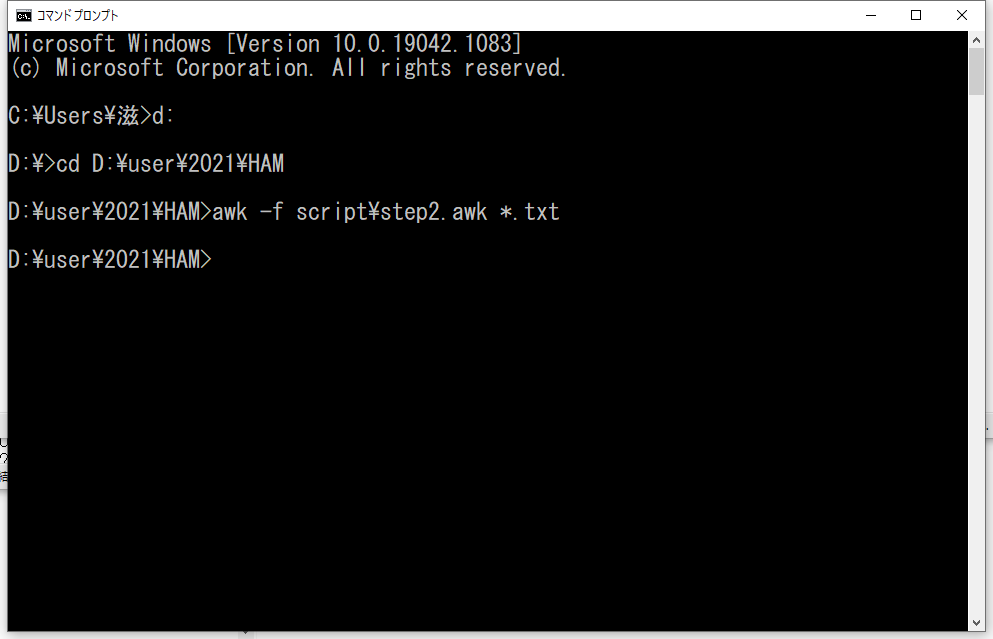
[cd]:チェンジ・ディレクトリという意味です。「ディレクトリ」と「フォルダ」は同じか? と思いますが、通常考える上では同じと思って問題はないと思います。CUIでは「ディレクトリ」で、GUIでは「フォルダ」としているようですが、厳密な意味の違いについてはネットで調べてください。
このフォルダには12か月分のデータがあります。つまり12ファイルあります。
「awk」はストリームエディタなのでコマンドラインから改行単位に1行ずつ読み込みながら処理をしていきます。全部で何行あるかは次回ご紹介するとして2分19秒かかりました。
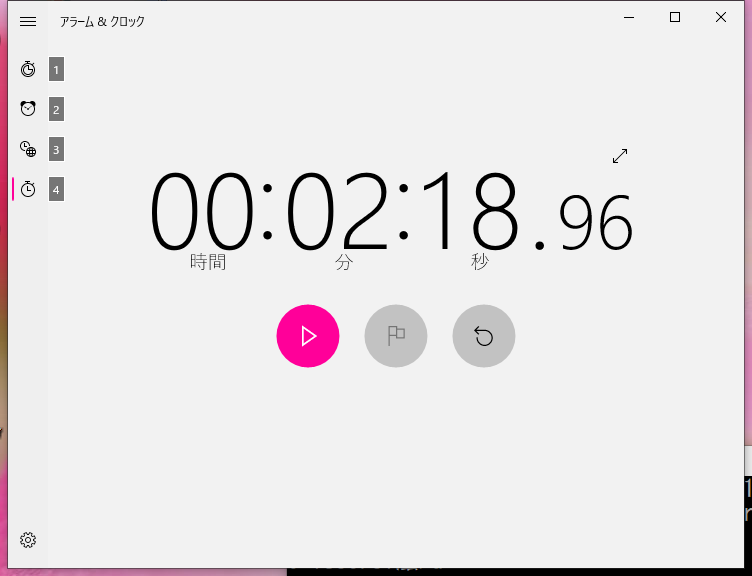
実は12ファイルで約1400万行あります。1行にタブが6個ありますので8400万個のタブをカンマに変換するのに140秒で終わっています。1秒に60万個の置換をしています。
スクリプト書くのに2分か3分くらいです。C言語で標準入力から拡張子「txt」のファイルを読み込んでカンマに置換する処理を2、3分で作ることはできないでしょう。
ここが「awk」のすごいところで手放すことができない理由になります。今日はここまで!

